overleaf template galleryLaTeX templates and examples — Recent
Discover LaTeX templates and examples to help with everything from writing a journal article to using a specific LaTeX package.

Template for IEEE Affective Computing and Intelligent Interaction (ACII) 2023

In nearly all videogames, creating smart and complex artificial agents helps ensure an enjoyable and challenging player experience. Using a dodgeball-inspired simulation, we attempt to train a population of robots to develop effective individual strategies against hard-coded opponents. Every evolving robot is controlled by a feedforward artificial neural network, and has a fitness function based on its hits and deaths. We evolved the robots using both standard and real-time NEAT against several teams. We hypothesized that interesting strategies would develop using both evolutionary algorithms, and fitness would increase in each trial. Initial experiments using rtNEAT did not increase fitness substantially, and after several thousand time steps the robots still exhibited mostly random movement. One exception was a defensive strategy against randomly moving enemies where individuals would specifically avoid the area near the center line. Subsequent experiments using the NEAT algorithm were more successful both visually and quantitatively: average fitness improved, and complex tactics appeared to develop in some trials, such as hiding behind the obstacle. Further research could improve our rtNEAT algorithm to match the relative effectiveness of NEAT, or use competitive coevolution to remove the need for hard-coded opponents.

A template for the Proceedings of the International Conference on Computing and Advances in Information Technology (ICCAIT 2023) 21-23 November 2023, Ahmadu Bello University, Zaria, Nigeria.

A simple template aims to write report or record progress

MATH 21-127: Concepts of Mathematics Template for homework submission READ THE FOLLOWING CAREFULLY!!! When you produce a PDF version of this document to turn in, change the filename to hwX-name.pdf replacing X with the homework assignment number and name with your last name.
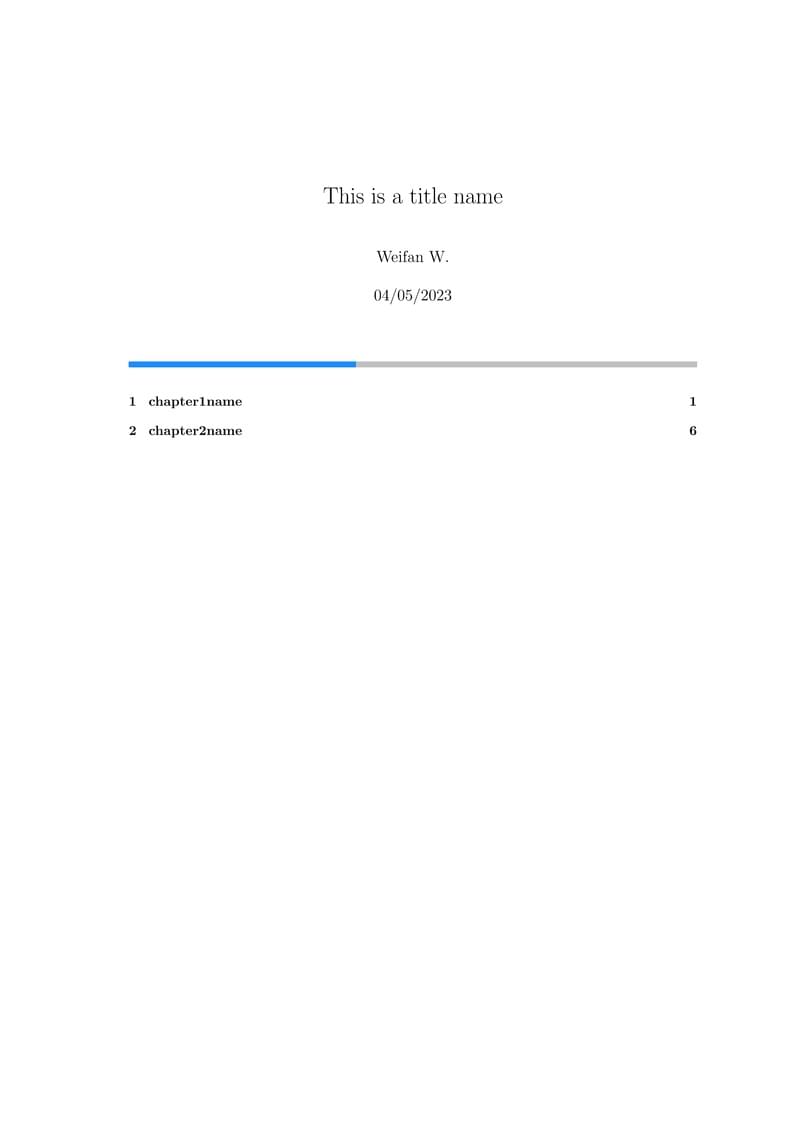
This package can help you format your notes easily and give them a unique front page for every chapter and section. It calculates your progress and then displays the progress bar under the title. It also displays a partial table of contents under every progress bar and only shows the subdirectories of the current part. To generate this, you can simply enter your current completed titles with a command that accepts Variable Arguments. Still, that also helped you review your notes. You can also customise the colour of the bar. For more information, go to https://ctan.org/pkg/unifront

Template for submitting Bachelor thesis specification. Special thanks to: Sudarsan Bhargavan

This is an unofficial poster template for Indiana University. It is a modified version of Gemini with minimal changes.

In this study we identify factors that affect a Major League Baseball (MLB) pitcher's salary. We are interested in knowing whether ability is a good indicator of compensation. To test this we created a model to predict the salaries of pitchers in the MLB.
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.