Community articles — Two-column
Kürzlich

A proof is given that the summation of all prime numbers can be assigned the value of 13/12, as well as values that can be assigned to the summation of all multiples and all odd multiples.

Collection of statistics formulae taken from the perennial text book Lind, Douglas A. et. al. (2015): Statistical Techniques in Business and Economics, 16 ed. (2015).

A performance time evaluation between a C lexer and a Lex generated lexer.
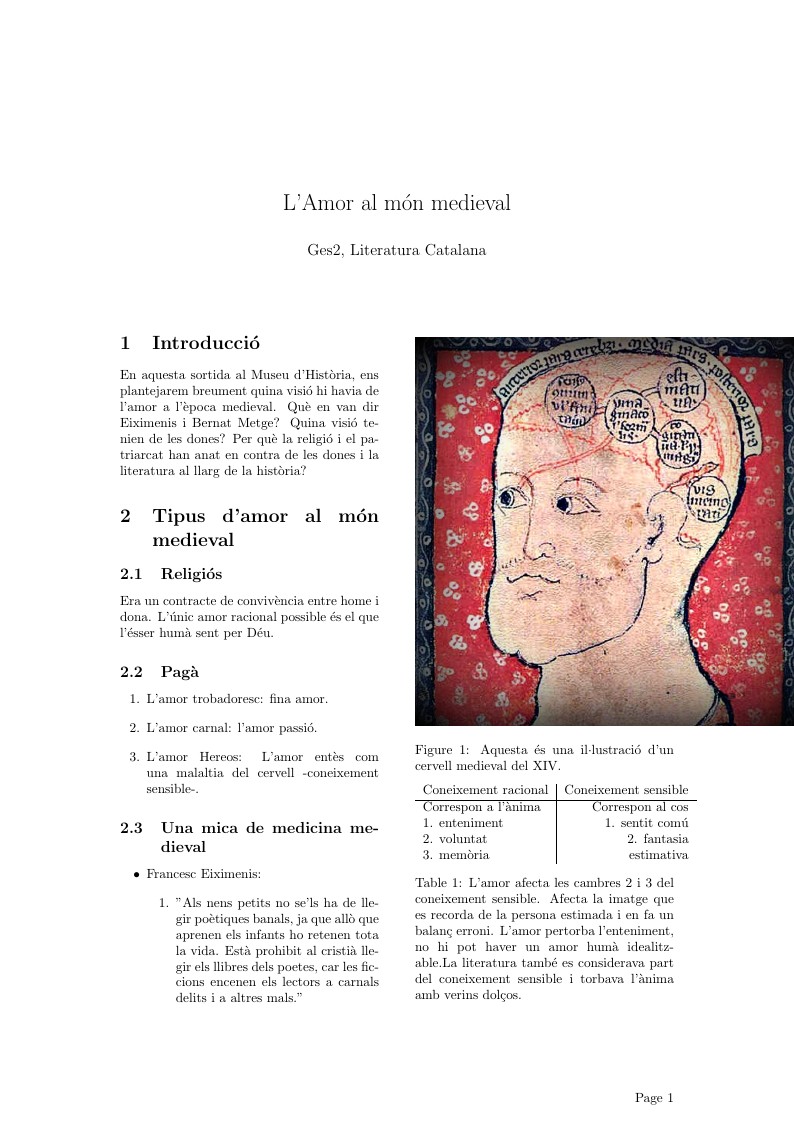
Breu resum sobre l'amor al món medieval. Basat en apunts de l'assignatura de la UB.

se presenta el desarrollo de un algoritmo bajo código fuente JavaScript para la solución de la ecuación de flujo crítico (2). Se implementó un lenguaje de programación orientado a objetos para sistemas Android 4.0 o superiores a partir de procesos iterativos e incrementales (Desarrollo ágil). Se utilizó el método numérico de Newton-Raphson para determinar la profundidad crítica de sietes secciones hidráulicas (Rectangular, trapezoidal, trapezoidal asimétrico, triangular, triangular asimétrico, parabólico y circular). Con el propósito de acelerar y garantizar el nivel de convergencia para cada una de las secciones se obtuvo una función potencial para establecer el valor semilla en el proceso iterativo, este valor se asocia de manera directa a las condiciones preestablecidas del problema hidráulico. La aplicación calcula la profundidad crítica, velocidad crítica, área

Created using the Deedy CV/Resume XeLaTeX Template Version 1.0 (5/5/2014) This template has been downloaded from: http://www.LaTeXTemplates.com Original author: Debarghya Das (http://www.debarghyadas.com) With extensive modifications by: Vel (vel@latextemplates.com)

En este informe se presenta detalladamente el desarrollo de la primera practica de laboratorio, en la cual encontramos la ley de ohm y sus aplicaciones en los circuitos en paralelo y en serie, teniendo en cuenta las normas de laboratorio para así lograr la correcta finalización de dicha guía.

Created using the Classicthesis-Styled CV LaTeX Template Version 1.0 (22/2/13) from LaTeXTemplates.com, originally by Alessandro Plasmati

The use of technological resources in education has lead to positive changes in the elaboration of new methodologies, in this context technologies such as the Digital Interactive Whiteboard (DIW) can act by facilitating Learning. The mere presence of the DIW does not guarantee benefits for the student's learning process, that raises doubts about whether or not the resources available are used in a satisfactory manner. In this research it was possible to verify that there are few tools available for the DIW context, and many of them have problems of usability and content quality. Thus, a form of facilitate the content elaboration for the DIW is the use of Authoring Tools (ATs). In order to verify whether or not the use of ATs promotes better use of the DIW, an AT (entitled AtauDIW) was developed to assist the use of DIWs.
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.